歌声鉴伪模型的训练方法、歌声鉴伪方法及相关产品与流程
本技术实施例涉及音频,尤其涉及歌声鉴伪模型的训练方法、歌声鉴伪方法及相关产品。
背景技术:
1、随着人工智能生成内容(aigc,artificial intelligence generated content)技术的发展,ai生成的歌声听起来越来越自然,对于一般人来说也已经较难进行鉴别。但是,未经授权模仿歌手的合成歌曲,通常会影响原版歌曲的受众量,引发版权或许可纠纷;此外,就主流意识而言,广大听众也难以接受听到的歌曲其实是ai生成而非真人献唱。
2、目前,相关的音频鉴伪技术大多是针对说话语音的,不能直接应用于歌声鉴伪,且专门针对歌声进行鉴伪的技术较为稀缺,需要专业人员考虑歌声中的唱法、技巧、气息、咬字或音高等声学因素,从而分析待测歌曲是否为ai演唱,分析过程较为复杂。面对海量发布的多样歌曲,如此依赖人工鉴别每首歌曲的一系列技巧因素,工作量大,且容易将ai演唱的歌声误认为真人歌声。故针对于此,迫切需要提供有效的解决方案。
技术实现思路
1、本技术实施例提供了歌声鉴伪模型的训练方法、歌声鉴伪方法及相关产品,用于提高对歌声的真伪鉴别效率。
2、本技术实施例第一方面提供一种歌声鉴伪模型的训练方法,所述歌声鉴伪模型包含歌声特征提取模型和目标分类器模型,所述训练方法包括:
3、从机器演唱的歌曲样本中提取各歌声片段作为正样本歌声片段,从真人演唱的歌曲样本中提取各歌声片段作为负样本歌声片段;所述歌声片段指,所述歌曲样本中去除伴奏和无歌声片段后的音频片段;
4、将所述正样本歌声片段、所述负样本歌声片段分别输入所述歌声特征提取模型,以提取所述正样本歌声片段和所述负样本歌声片段各自对应的歌声特征;其中,所述歌声特征提取模型为,朝着训练目标训练好的特征提取模型;所述训练目标包括,减小所述正样本歌声片段之间的距离,并增大所述正样本歌声片段和所述负样本歌声片段之间的距离;
5、使用所述正样本歌声片段和所述负样本歌声片段各自对应的标签信息、所述歌声特征,对初始分类器模型进行训练,直至满足收敛条件时停止训练,得到所述目标分类器模型;所述标签信息用于标记歌声片段是否为机器演唱,所述目标分类器模型用于输出待测歌曲中的歌声片段为机器演唱片段的预测概率,以判断所述待测歌曲是否为机器演唱。
6、可选地,从机器演唱的歌曲样本中提取各歌声片段作为正样本歌声片段之后,所述训练方法还包括:
7、对所述正样本歌声片段进行增强处理,以生成同样属于机器演唱的更多正样本歌声片段。
8、可选地,提取所述正样本歌声片段和所述负样本歌声片段各自对应的歌声特征之后,所述训练方法还包括:
9、从所述正样本歌声片段和所述负样本歌声片段各自对应的歌声特征中,至少区分出歌声表征特征用以对初始分类器模型进行训练;所述歌声表征特征至少用于,表征所述歌声片段中人声信号的演唱节奏和/或情感变化。
10、可选地,所述使用所述正样本歌声片段和所述负样本歌声片段各自对应的标签信息、所述歌声特征对初始分类器模型进行训练,包括:
11、将所述正样本歌声片段和所述负样本歌声片段各自对应的歌声特征中,除歌声表征特征之外的特征作为歌声辅助特征;所述歌声表征特征至少用于,表征所述歌声片段中人声信号的演唱节奏和/或情感变化;
12、使用所述正样本歌声片段、所述负样本歌声片段,以及所述正样本歌声片段和所述负样本歌声片段各自对应的标签信息、所述歌声辅助特征,对所述初始分类器模型和所述歌声特征提取模型中的歌声表征模型进行联合训练,以得到所述目标分类器模型和训练好的歌声表征模型;
13、其中,所述训练好的歌声表征模型符合所述训练目标,所述歌声表征模型被训练时的学习率小于所述初始分类器模型被训练时的学习率;所述训练好的歌声表征模型用于,通过歌声片段的时域信号输出所述歌声片段对应的歌声表征特征。
14、可选地,若所述歌声辅助特征包含不同类型的多类特征,所述训练方法还包括:
15、对所述多类特征进行加权融合,得到辅助特征融合结果;所述辅助特征融合结果至少用于训练所述初始分类器模型。
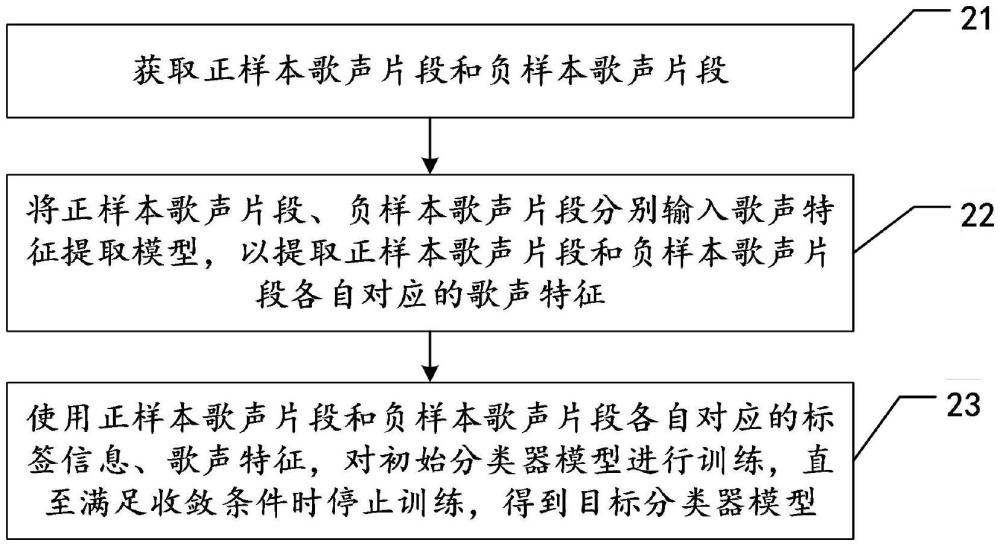
16、可选地,所述获取歌曲样本集中的各歌声片段,包括:
17、收集机器演唱的正样本歌曲、真人演唱的负样本歌曲;
18、针对正样本歌曲和负样本歌曲中的当前样本歌曲,对存在伴奏的所述当前样本歌曲进行声乐分离,以去除所述当前样本歌曲中的伴奏;
19、去除所述当前样本歌曲中的无歌声片段,并将所述当前样本歌曲中的歌声片段进行拼接;
20、针对所述当前样本歌曲,对去除伴奏且去除无歌声片段后的拼接片段进行切片,以得到预设长度的歌声片段。
21、可选地,若融合概率大于等于目标判断阈值,所述融合概率由样本歌曲中各歌声片段的所述预测概率融合得到的,则确定所述样本歌曲为机器演唱的歌曲;所述目标判断阈值的确定过程,包括:
22、基于各歌曲样本的预测数量和真实数量之间的比例结果,调整所述目标分类器模型初始分配到的初始判断阈值,直至所述初始判断阈值被调至影响所述比例结果符合预设结果时停止调整,得到目标判断阈值;
23、其中,所述预测数量指各歌曲样本中,被所述目标分类器模型基于所述初始判断阈值预测为机器演唱的歌曲数,所述真实数量指各歌曲样本中实际为机器演唱的歌曲数。
24、本技术第一方面所述的方法在具体实施时可采用本技术第二方面所述的内容实现。
25、本技术实施例第二方面提供一种歌声鉴伪方法,包括:
26、获取待测歌曲中的各歌声片段;
27、将各所述歌声片段输入歌声鉴伪模型,以得到各所述歌声片段被预测为机器演唱片段的预测概率;所述歌声鉴伪模型根据第一方面或第一方面的任一具体实现方式所述的训练方法训练得到;
28、对各所述歌声片段的所述预测概率进行融合计算,得到所述待测歌曲对应的融合概率;
29、若所述融合概率大于等于目标判断阈值,则确定所述待测歌曲为机器演唱的歌曲。
30、可选地,若所述歌声鉴伪模型有多个,且各所述歌声鉴伪模型之间的歌曲样本存在类型差别,所述类型差别不包含机器演唱或真人演唱的区分,则所述歌声鉴伪方法还包括:
31、获得所述待测歌曲通过各所述歌声鉴伪模型分别算得的融合概率;
32、基于各所述歌声鉴伪模型的融合概率,综合确定所述待测歌曲是否为机器演唱的歌曲。
33、可选地,将各所述歌声片段输入歌声鉴伪模型,以得到各所述歌声片段被预测为机器演唱片段的预测概率之后,所述歌声鉴伪方法还包括:
34、若多个所述预测概率之间的差距超出预设差距,则确定所述待测歌曲为机器和真人合唱的歌曲。
35、本技术实施例第三方面提供一种电子设备,包括:
36、中央处理器,存储器以及输入输出接口;
37、所述存储器为短暂存储存储器或持久存储存储器;
38、所述中央处理器配置为与所述存储器通信,并执行所述存储器中的指令操作以执行本技术实施例第一方面或第一方面的任一具体实现方式所描述的方法。
39、本技术实施例第四方面提供一种计算机可读存储介质,包括指令,当所述指令在计算机上运行时,使得计算机执行如本技术实施例第一方面或第一方面的任一具体实现方式所描述的方法。
40、本技术实施例第五方面提供一种包含指令或计算机程序的计算机程序产品,当所述计算机程序产品在计算机上运行时,使得计算机执行如本技术实施例第一方面或第一方面的任一具体实现方式所描述的方法。
41、从以上技术方案可以看出,本技术实施例至少具有以下优点:
42、选取标签不同的正样本歌声片段和负样本歌声片段,有助于为歌声鉴伪模型的训练提供充足可靠的数据支持,促使歌声鉴伪模型更深刻地识别待测歌曲中的歌声片段。其中,采用歌声特征提取模型提取各歌声片段的歌声特征,可有效替代人工快而准地学习到机器演唱和真人演唱之间的声学差异,以保障目标分类器模型鉴别歌曲真伪时的效率和准确度,同时,填补对机器生成歌声进行检测的技术空缺。
技术研发人员:汪照文,江益靓,孔令城,赵伟峰,周文江,徐雨晴,吕烨子,林艳秋
技术所有人:腾讯音乐娱乐科技(深圳)有限公司
备 注:该技术已申请专利,仅供学习研究,如用于商业用途,请联系技术所有人。
声 明 :此信息收集于网络,如果你是此专利的发明人不想本网站收录此信息请联系我们,我们会在第一时间删除