一种音频处理方法、装置、电子设备及存储介质与流程
本技术涉及音频处理,尤其是涉及一种音频处理方法、装置、电子设备及存储介质。
背景技术:
1、无论是在图像、视频还是音频中,传统的压缩算法的思路集中在减少数据序列中的冗余,减少文件大小,但是压缩算法会从原始信息中丢失一些信息。神经压缩技术作为一种新的方法正在迅速兴起,该方法采用神经网络来表示压缩和重建数据,实现高压缩率的同时实现低感知信息损失。类似地,语音波形可以被转换成矢量格式并解码以重新生成声音。虽然soundstream和encodec可以实现很好的压缩性能和重建表现,但是实现好的重构性能需要很多码本(codebooks),这增加了生成模型的压力和计算开销。为了保持神经网络音频压缩模型性能的同时,减少计算开销和推理时间开销,hificodec提出分组残差矢量量化技术,将中间特征分组,对每一组分别采取残差矢量量化技术来量化压缩,最后,组合分组量化后的特征来解码,因此可以保持较好重建效果的同时,使用更少的码本来重建音频。但是hificodec采取分组残差矢量量化技术来减少重建的码本,分组量化的同时会引入模型学习的偏差,导致重建的时候对音频质量产生影响。所以,如何提高重建的音频质量成为了不容小觑的技术问题。
技术实现思路
1、有鉴于此,本技术的目的在于提供一种音频处理方法、装置、电子设备及存储介质,结合声码器监督分支的语音处理模型可以把音频信号编码为离散的表示,在声码器的辅助监督下提高重建的音频质量,保证模型性能不降低的情况下提高处理速度。
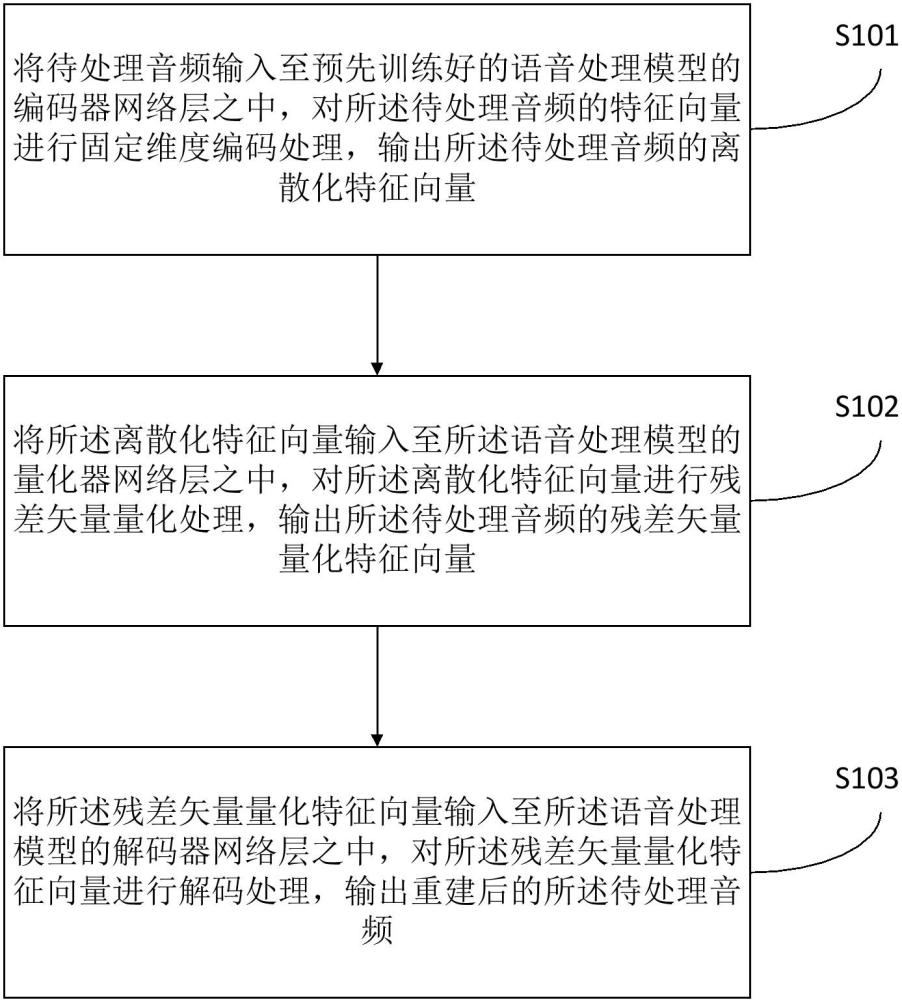
2、本技术实施例提供了一种音频处理方法,所述音频处理方法包括:
3、将待处理音频输入至预先训练好的语音处理模型的编码器网络层之中,对所述待处理音频的特征向量进行固定维度编码处理,输出所述待处理音频的离散化特征向量;
4、将所述离散化特征向量输入至所述语音处理模型的量化器网络层之中,对所述离散化特征向量进行残差矢量量化处理,输出所述待处理音频的残差矢量量化特征向量;
5、将所述残差矢量量化特征向量输入至所述语音处理模型的解码器网络层之中,对所述残差矢量量化特征向量进行解码处理,输出重建后的所述待处理音频;其中,所述语音处理模型是基于目标声码器监督分支对神经网络模型进行迭代训练得到的。
6、在一种可能的实施方式之中,通过以下步骤确定出所述语音处理模型:
7、将第一样本音频的梅尔谱特征输入至预先训练好的目标声码器之中,对所述梅尔谱特征进行重建处理,输出所述第一样本音频的第一重建音频波形;其中,所述目标声码器的生成器采用的是一维深度可分离卷积;
8、将所述第一样本音频输入至所述神经网络模型之中,基于初始编码器网络层、初始量化器网络层以及初始解码器网络层进行处理,输出重建后的所述第一样本音频;
9、将重建后的所述第一样本音频输入至所述目标声码器之中,确定出重建后的所述第一样本音频与所述第一重建音频波形之间的第一损失值;
10、基于所述第一损失值、所述初始编码器网络层的第二损失值、所述初始量化器网络层的第三损失值以及所述初始解码器网络层的第四损失值对所述神经网络模型进行迭代训练,确定出所述语音处理模型。
11、在一种可能的实施方式之中,所述将第一样本音频的梅尔谱特征输入至预先训练好的目标声码器之中,对所述梅尔谱特征进行重建处理,输出所述第一样本音频的第一重建音频波形,包括:
12、将所述梅尔谱特征输入至目标声码器的生成器之中,基于所述生成器对所述梅尔谱特征在时间维度上进行第一次卷积处理,生成第一次卷积处理后的所述梅尔谱特征;
13、基于所述生成器对第一次卷积处理后的所述梅尔谱特征在空间维度上进行第二次卷积处理,生成所述第一样本音频的第一重建音频波形。
14、在一种可能的实施方式之中,通过以下步骤对确定出所述目标声码器:
15、将初始声码器中的初始生成器的一维卷积替换为一维深度可分离卷积,得到替换后的初始声码器;
16、将第二样本音频的梅尔谱特征输入至替换后的初始声码器的初始生成器之中进行处理,生成所述第二样本音频的第二重建音频波形;
17、将所述第二样本音频的重建音频波形输入至替换后的初始声码器的判别器之中,对所述第二重建音频波形进行多尺度以及多周期的音频鉴定处理,确定出所述第二重建音频波形的真伪类别;
18、若所述第二重建音频波形的类别为伪类别,则对替换后的初始声码器的网络参数进行更改,继续对替换后的初始声码器进行迭代训练,直至所述第二重建音频波形的类别为真类别时停止迭代训练确定出所述目标声码器。
19、在一种可能的实施方式之中,所述基于所述第一损失值、所述初始编码器网络层的第二损失值、所述初始量化器网络层的第三损失值以及所述初始解码器网络层的第四损失值对所述神经网络模型进行迭代训练,确定出所述语音处理模型,包括:
20、对所述第一损失值、所述第二损失值、所述第三损失值以及所述第四损失值进行加权处理,确定出总损失值;
21、若所述总损失值小于等于预设损失阈值,则将所述神经网络模型作为所述语音处理模型,若所述总损失值大于所述预设损失阈值,则对所述神经网络模型的网络参数进行更改,继续对更改后的所述神经网络模型进行迭代训练。
22、在一种可能的实施方式之中,所述将所述第一样本音频输入至所述神经网络模型之中,基于初始编码器网络层、初始量化器网络层以及初始解码器网络层进行处理,输出重建后的所述第一样本音频,包括:
23、将所述第一样本音频输入至所述初始编码器网络层之中进行固定维度编码处理,输出样本离散化特征向量;
24、将所述样本离散化特征向量输入至所述初始量化器网络层之中进行残差矢量量化处理,输出样本残差矢量量化特征向量;
25、将所述样本残差矢量量化特征向量输入至所述初始解码器网络层之中进行解码处理,输出重建后的所述第一样本音频。
26、在一种可能的实施方式之中,通过以下方式确定出所述第二损失值、所述第三损失值以及所述第四损失值:
27、获取所述第一样本音频的标签信息;其中,所述标签信息包括实际离散化特征向量、实际残差矢量量化特征向量、量化后的实际音频;
28、基于损失函数对所述实际离散化特征向量以及所述样本离散化特征向量进行计算,确定出所述第二损失值;
29、基于所述损失函数对所述实际残差矢量量化特征向量以及所述样本残差矢量量化特征向量进行计算,确定出所述第三损失值;
30、基于所述损失函数对所述量化后的实际音频以及重建后的所述第一样本音频进行计算,确定出所述第四损失值。
31、本技术实施例还提供了一种音频处理装置,所述音频处理装置包括:
32、编码处理模块,用于将待处理音频输入至预先训练好的语音处理模型的编码器网络层之中,对所述待处理音频的特征向量进行固定维度编码处理,输出所述待处理音频的离散化特征向量;
33、量化处理模块,用于将所述离散化特征向量输入至所述语音处理模型的量化器网络层之中,对所述离散化特征向量进行残差矢量量化处理,输出所述待处理音频的残差矢量量化特征向量;
34、解码处理模块,用于将所述残差矢量量化特征向量输入至所述语音处理模型的解码器网络层之中,对所述残差矢量量化特征向量进行解码处理,输出重建后的所述待处理音频;其中,所述语音处理模型是基于目标声码器监督分支对神经网络模型进行迭代训练得到的。
35、本技术实施例还提供一种电子设备,包括:处理器、存储器和总线,所述存储器存储有所述处理器可执行的机器可读指令,当电子设备运行时,所述处理器与所述存储器之间通过总线通信,所述机器可读指令被所述处理器执行时执行如上述的音频处理方法的步骤。
36、本技术实施例还提供一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行如上述的音频处理方法的步骤。
37、本技术实施例提供的一种音频处理方法、装置、电子设备及存储介质,所述音频处理方法包括:将待处理音频输入至预先训练好的语音处理模型的编码器网络层之中,对所述待处理音频的特征向量进行固定维度编码处理,输出所述待处理音频的离散化特征向量;将所述离散化特征向量输入至所述语音处理模型的量化器网络层之中,对所述离散化特征向量进行残差矢量量化处理,输出所述待处理音频的残差矢量量化特征向量;将所述残差矢量量化特征向量输入至所述语音处理模型的解码器网络层之中,对所述残差矢量量化特征向量进行解码处理,输出重建后的所述待处理音频;其中,所述语音处理模型是基于目标声码器监督分支对神经网络模型进行迭代训练得到的。结合声码器监督分支的语音处理模型可以把音频信号编码为离散的表示,在声码器的辅助监督下提高重建的音频质量,保证模型性能不降低的情况下提高处理速度。
38、为使本技术的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
技术研发人员:张德俊,王秋明
技术所有人:北京远鉴信息技术有限公司
备 注:该技术已申请专利,仅供学习研究,如用于商业用途,请联系技术所有人。
声 明 :此信息收集于网络,如果你是此专利的发明人不想本网站收录此信息请联系我们,我们会在第一时间删除